How to block specific user agents on Nginx web server
Last updated on September 21, 2020 by Dan Nanni
The modern Internet is infested with various malicious robots and crawlers such as malware bots, spambots or content scrapers which are scanning your website in surreptitious ways, for example to detect potential website vulnerabilities, harvest email addresses, or just to steal content from your website. Many of these robots can be identified by their signature "user-agent" string.
As a first line of defense, you could try to block malicious bots from accessing your website by blacklisting their user-agents in robots.txt file. However, unfortunately this works only for well-behaving robots which are designed to obey robots.txt. Many malicious bots can simply ignore robots.txt and scan your website at will.
An alternative way to block particular robots is to configure your web server, such that it refuses to serve content to requests with certain user-agent strings. This post explains how to block certain user-agent on nginx web server. I assume that you already have an Nginx web server up and running.
Blacklist Certain User-Agents in Nginx
To configure user-agent block list, open the nginx configuration file of your website, where the server section is defined. This file can be found in different places depending on your nginx setup or Linux distribution (e.g., /etc/nginx/nginx.conf, /etc/nginx/sites-enabled/<your-site>, /usr/local/nginx/conf/nginx.conf, /etc/nginx/conf.d/<your-site>).
server {
listen 80 default_server;
server_name xmodulo.com;
root /usr/share/nginx/html;
....
}
Once you open the config file with the server section, add the following if statement(s) somewhere inside the section.
server {
listen 80 default_server;
server_name xmodulo.com;
root /usr/share/nginx/html;
# case sensitive matching
if ($http_user_agent ~ (Antivirx|Arian)) {
return 403;
}
# case insensitive matching
if ($http_user_agent ~* (netcrawl|npbot|malicious)) {
return 403;
}
....
}
As you can guess, these if statements match any bad user-agent string with regular expressions, and return 403 HTTP status code when a match is found. $http_user_agent is a variable that contains the user-agent string of an HTTP request. The ~ operator does case-sensitive matching against user-agent string, while the ~* operator does case-insensitive matching. The | operator is logical-OR, so you can put as many user-agent keywords in the if statements, and block them all.
After modifying the configuration file, you must reload nginx to activate the blocking:
$ sudo /path/to/nginx -s reload
You can test user-agent blocking by using wget or curl with --user-agent option.
$ wget --user-agent "malicious bot" http://<nginx-ip-address>
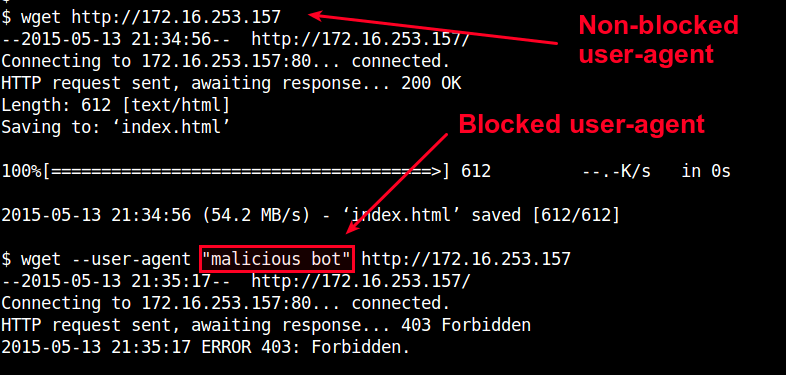
Manage User-Agent Blacklist in Nginx
So far, I have shown how to block HTTP requests with a few user-agents in nginx. What if you have many different types of crawling bots to block?
Since the user-agent blacklist can grow very big, it is not a good idea to put them all inside your nginx's server section. Instead, you can create a separate file which lists all blocked user agents. For example, let's create /etc/nginx/useragent.rules, and define a map with all blocked user agents in the following format.
$ sudo vi /etc/nginx/useragent.rules
map $http_user_agent $badagent {
default 0;
~*malicious 1;
~*backdoor 1;
~*netcrawler 1;
~Antivirx 1;
~Arian 1;
~webbandit 1;
}
Similar to the earlier setup, the ~* operator will match a keyword in case-insensitive manner, while the ~ operator will match a keyword using a case-sensitive regular expression. The line that says default 0 means that any other user-agent not listed in the file will be allowed.
Next, open an nginx configuration file of your website, which contains http section, and add the following line somewhere inside the http section.
http {
.....
include /etc/nginx/useragent.rules
}
Note that this include statement must appear before the server section (this is why we add it inside http section).
Now open an nginx configuration where your server section is defined, and add the following if statement:
server {
....
if ($badagent) {
return 403;
}
....
}
Finally, reload nginx.
$ sudo /path/to/nginx -s reload
Now any user-agent which contains a keyword listed in /etc/nginx/useragent.rules will be automatically banned by nginx.
Support Xmodulo
This website is made possible by minimal ads and your gracious donation via PayPal or credit card
Please note that this article is published by Xmodulo.com under a Creative Commons Attribution-ShareAlike 3.0 Unported License. If you would like to use the whole or any part of this article, you need to cite this web page at Xmodulo.com as the original source.

Xmodulo © 2021 ‒ About ‒ Write for Us ‒ Feed ‒ Powered by DigitalOcean